164种盈利交易策略
以及如何生成更多10,000种策略

正如我在上一篇文章中提到的(点击查看),我设计并开发了一种借助生成式AI快速构建交易系统的方法。虽然这听起来像是灾难的配方,但通过将问题限制在一个非常具体的子集并仅关注少数几个因素,结果实际上非常惊人。
从875个候选策略中,我手动筛选出259个有潜力的策略。通过主成分分析(Principal Component Analysis),我发现许多策略在利用的因素上存在“重叠”。最终,我将列表精简为164种全新且独特的投资组合分配系统,这些系统往往优于我所参考的最先进基准。
我是如何做到的
想先探索这些策略?点击下方查看164种交易策略目录:
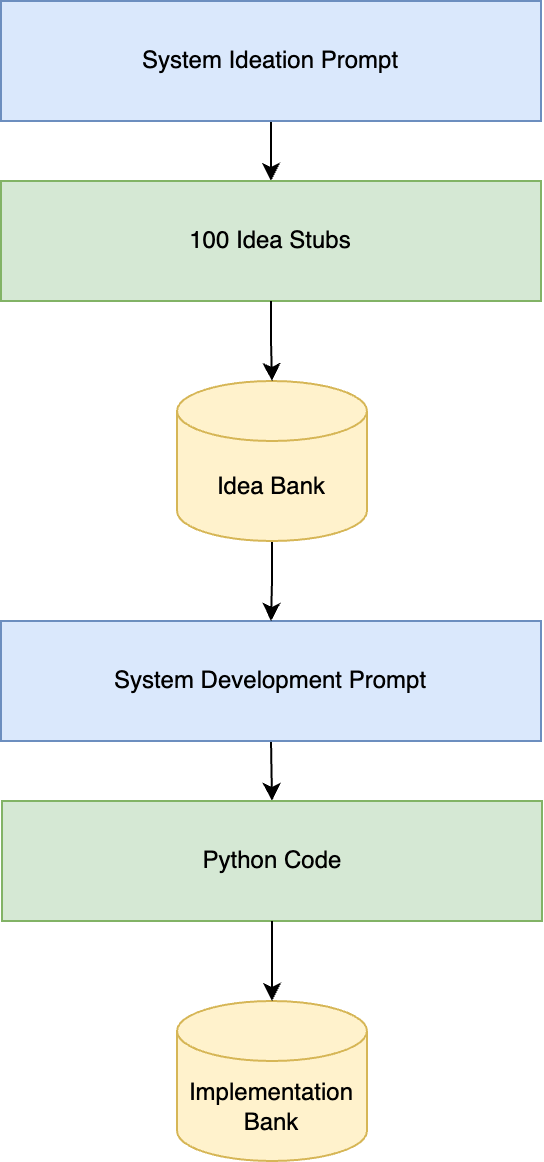
流程
创意生成
原始生成过程非常简单。正如我在上一篇文章(点击查看)中讨论的,我将问题分解为一个非常具体且抽象的需求。我只需要开发一个单一功能,输入输出格式、数值范围、预期等都有明确要求。因此,我设计了一个简洁、明确且强大的提示(prompt),用于生成创意(参见此处)。每次生成可一次性产出100个创意,输入到大型语言模型(LLM)后,我特别关注技术分析系统以保持简洁。
生成的输出是类似这样的创意草稿:
- Adaptive EMA Crossover
- 使用短期和长期EMA,其长度根据近期波动率调整(波动率高→EMA周期短)。
- Scores = current_price × (EMA_short/EMA_long)。
- Volatility-Scaled Momentum
- 在窗口期内计算动量并除以近期实现波动率。
- Scores ∝ momentum/σ,倾向于稳定的强趋势。
- RSI Extremum Reversion
- 对每项资产计算窗口期内的RSI;若RSI>70,score = current_price×(1–(RSI–70)/30);若<30,score=current_price×(1+(30–RSI)/30);否则为当前价格。
- Bollinger Band Trend
- 基于移动平均线构建±2σ带;价格突破上带时,score = current_price×(1 + breach_pct);突破下带时,score=current_price×(1 – breach_pct);在带内时回归均值。
- Keltner Channel Fade
- 使用基于ATR的通道;内部移动时scores = channel_midpoint,触及通道时score = current_price × (1 – sign(touch)_k_(distance/channel_width))。
这些草稿都被存入一个单一文本文件。我生成了875种独特策略,但感觉系统开始重复生成类似策略,于是进入实施阶段。
实施阶段
随后,我使用了相同的提示,但稍作修改用于代码生成。我每次生成20个系统,分批输出到一个“实施库”中,基本上就是一个文件列表。
验证阶段
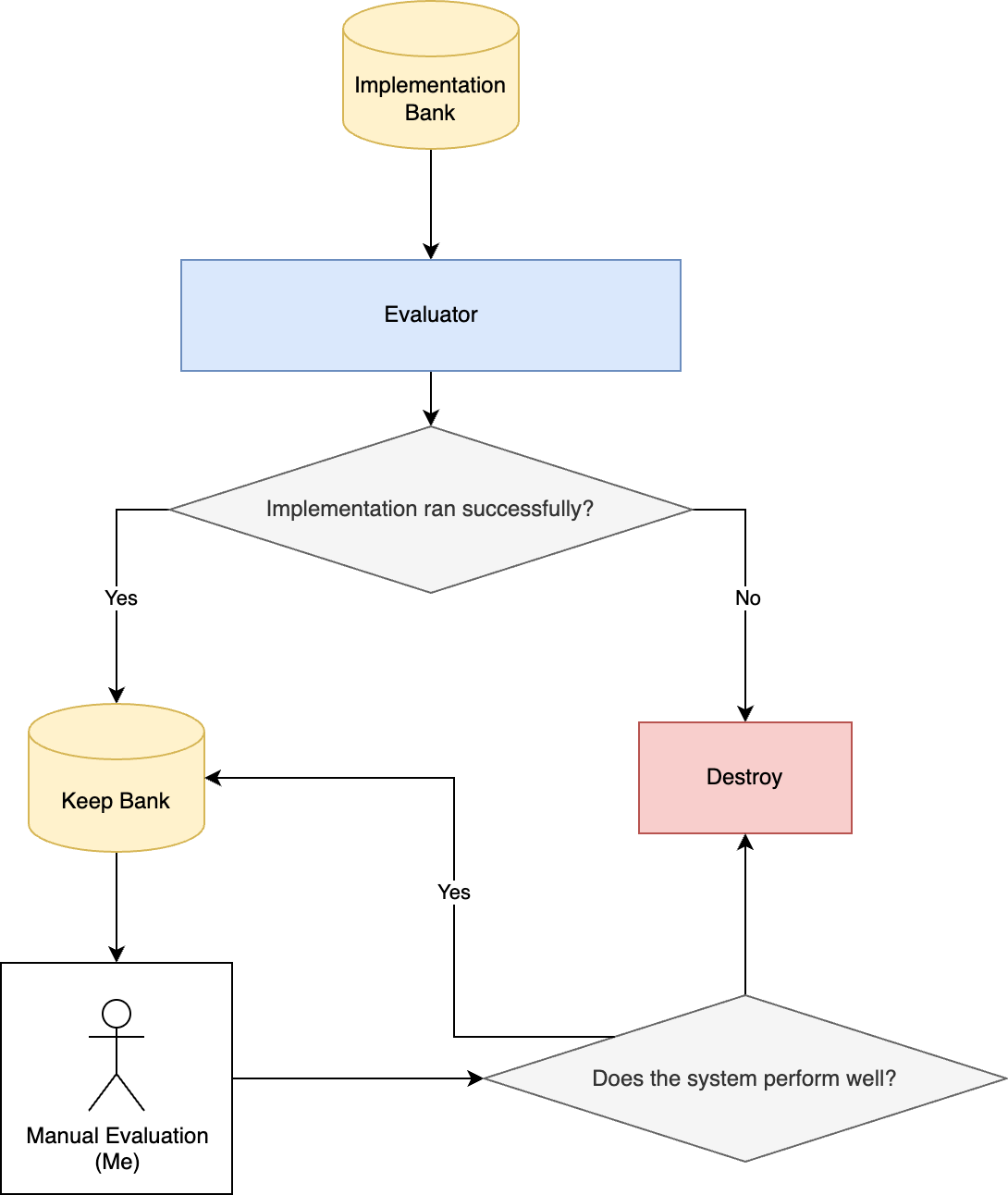
875个编程策略已经不错,但我需要一种方法来筛选它们。我编写了一个简单的评估器,读取所有文件,提取类,并在我的`portwine`回测系统内运行(点击获取)。
评估器输出权益曲线可视化、交易费用分析以及原始输出,以便未来进一步评估。不出所料,部分策略存在错误,因此我不得不调试和修复一些问题,整合代码等。即使如此,某些策略仍然格式错误,被淘汰。
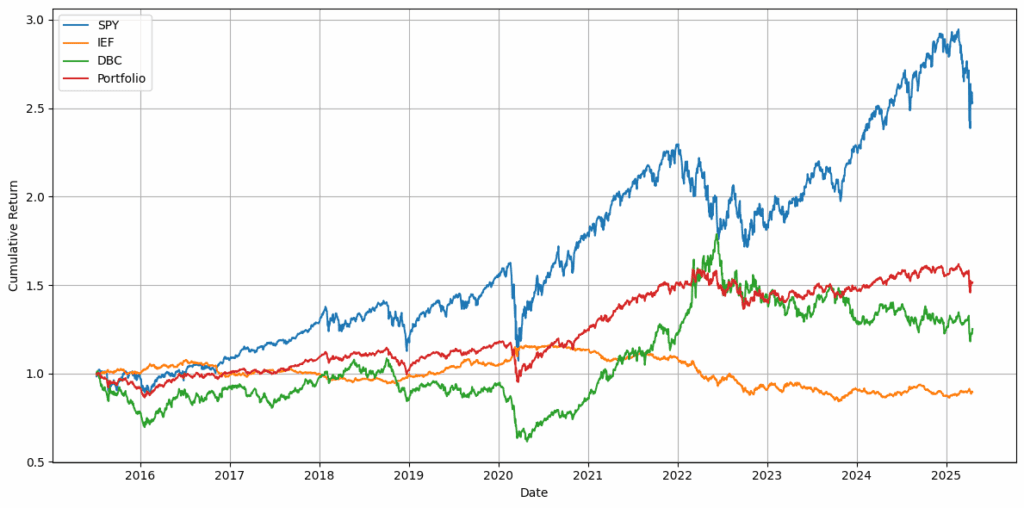
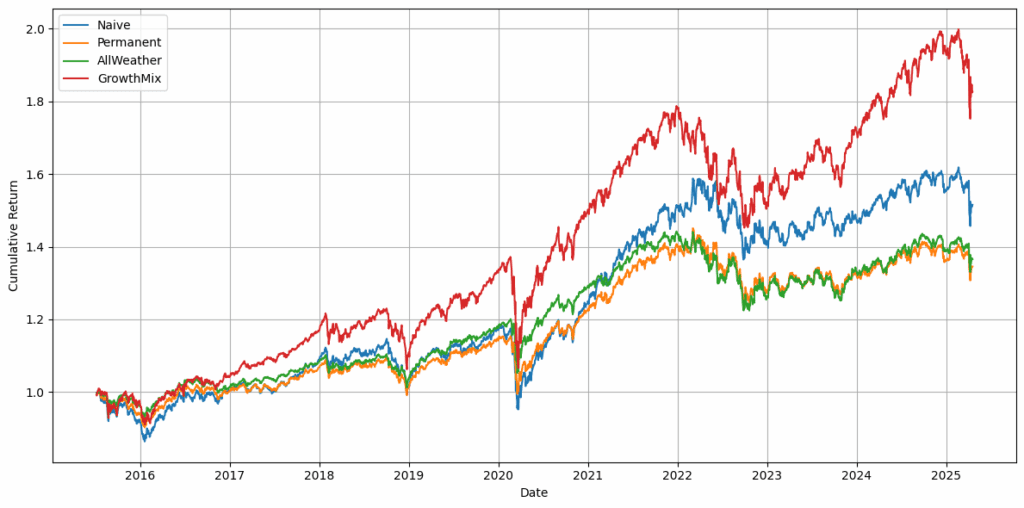
在尽可能多地获取策略输出后,我手动浏览了大量图像文件夹。我在单一资产组合(CL, KO, PG, PEP, MMM, TGT, JNJ, LOW, MDT, MCD)上运行每个策略以保持简单,并测试了8种回溯窗口和再平衡周期配置(7天回溯每周再平衡、30天回溯每月再平衡等)。
如果一个策略在每种配置下持续优于等权重基准,则保留,否则丢弃,最终剩下259个策略。
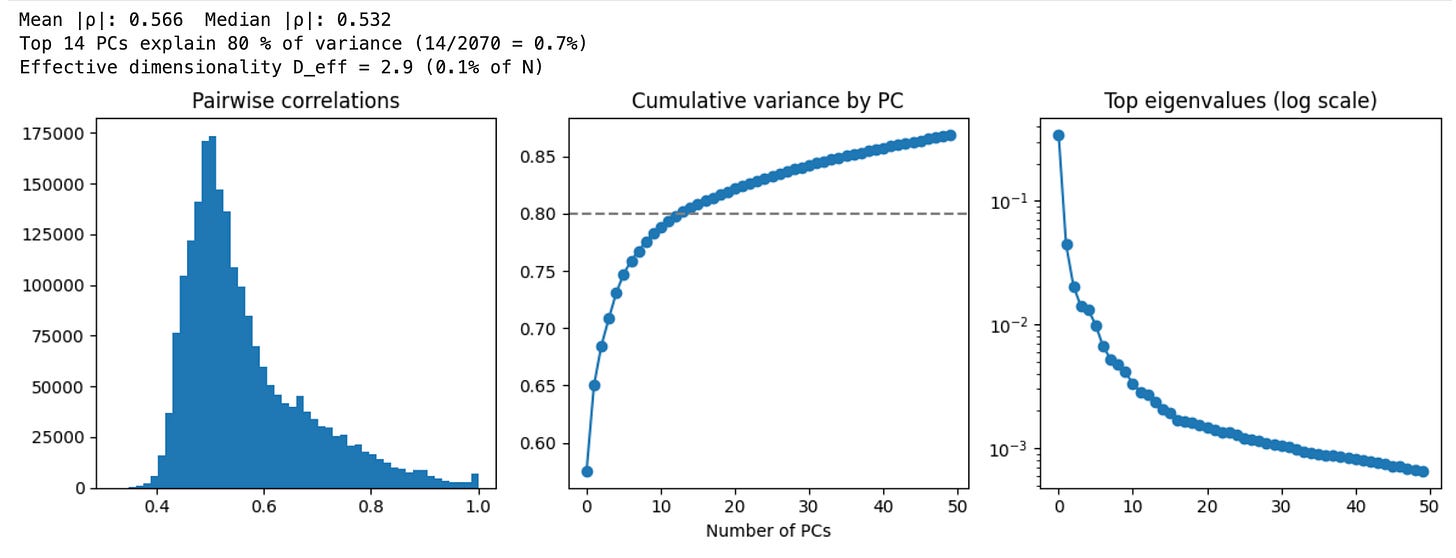
随后我进行了PCA分析,以了解策略之间的相似度。发现80%的方差仅由14个系统解释,集中度极高。注意,此例中策略总数为2070,因为每个参数配置被视为一个独立的“策略”。
为去除重复,我运行了一个简单的相关性过滤,淘汰高度相关的系统。可以使用更复杂的方法深入分析PCA结果,但对我来说这已足够。
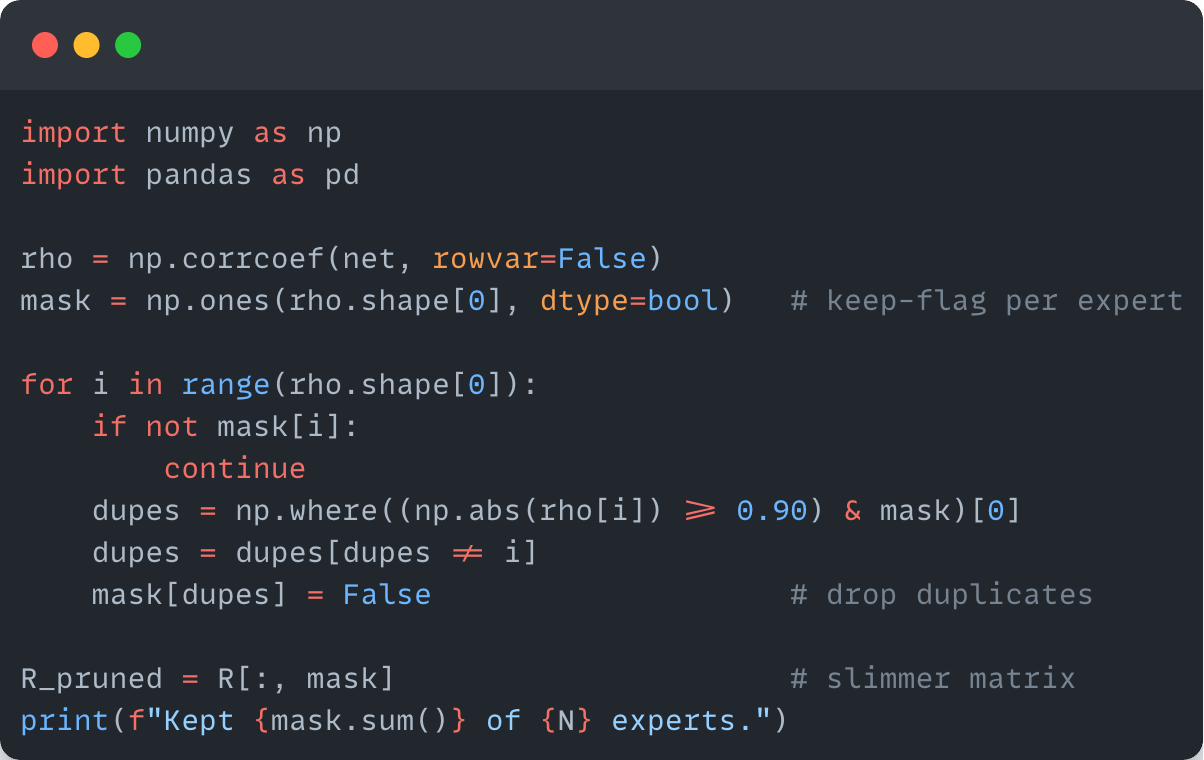
最终结果?保留了164种策略,占比18.75%。以下是它们的表现。
策略分类
最终策略分为以下类别,其中均值回归和动量策略占比最高。这并不令人意外,因为我用来创建这个元系统的基本模型特别使用了这两个因素。
- 均值回归策略(Mean Reversion Strategies)
- 价格预期在偏离后回归中心趋势。
- 趋势跟随/动量策略(Trend Following / Momentum Strategies)
- 价格预期沿当前方向继续。
- 基于移动平均线的预测(Moving Average Based Predictions)
- MA本身(或其投影)作为价格预测。
- 统计与时间序列建模(Statistical & Time Series Modeling)
- 使用正式统计模型预测价格。
- 信号处理与过滤方法(Signal Processing & Filtering Approaches)
- 应用滤波器去噪价格序列或识别主导频率。
- 基于模式和事件的策略(Pattern-Based & Event-Driven Strategies)
- 由特定图表模式或事件触发的预测。
- 横截面相对价值与统计套利(Cross-Sectional Relative Value & Statistical Arbitrage)
- 利用资产间的相对错定价或协同运动。
- 波动率与范围策略(Volatility & Range Based Strategies)
- 直接使用波动率或价格范围特征进行预测,而不仅是构建区间。
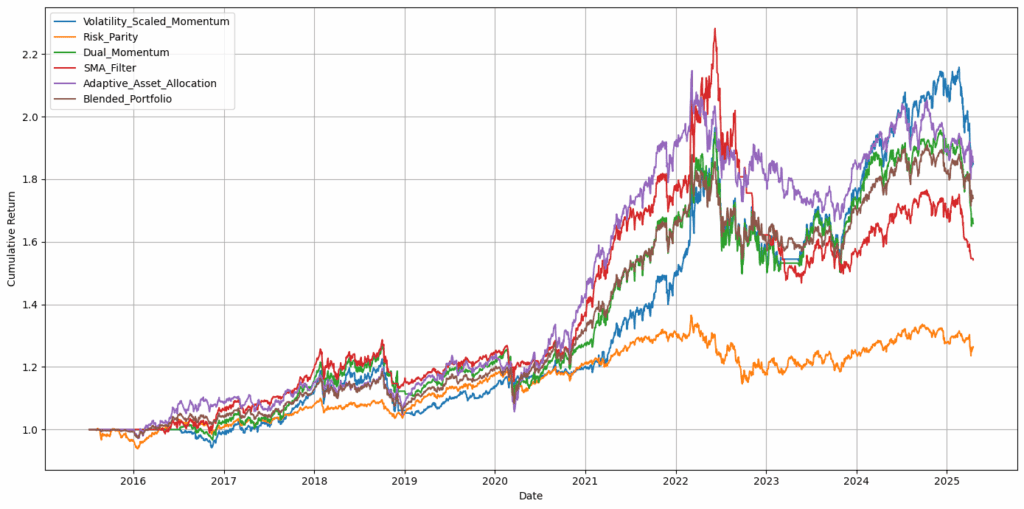
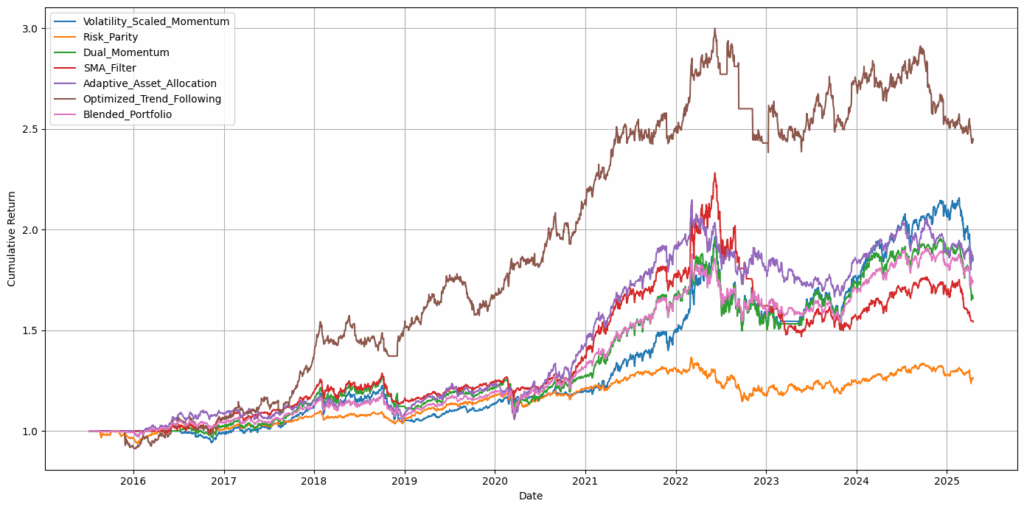
前三大策略
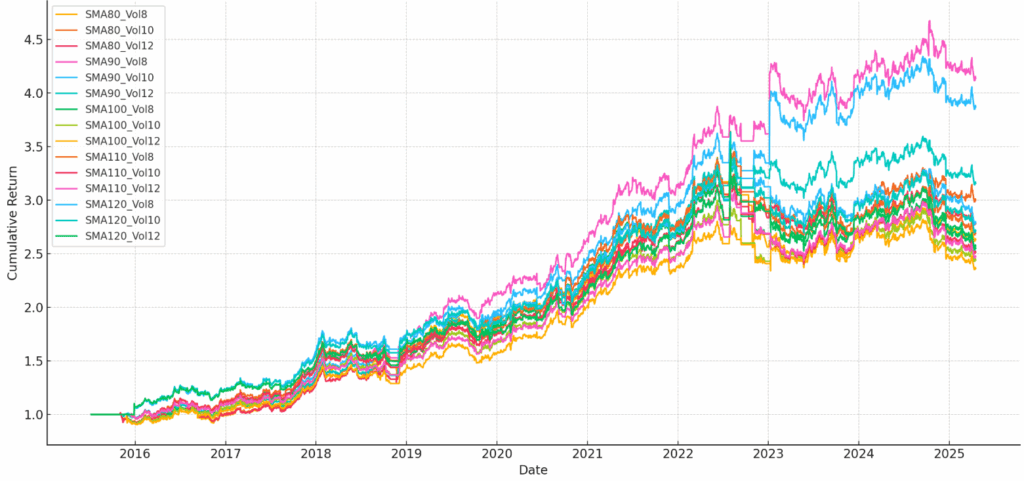
在164种策略中,三种策略脱颖而出,月度再平衡策略的年化复合增长率(CAGR)均超过20%,表现极为强劲。
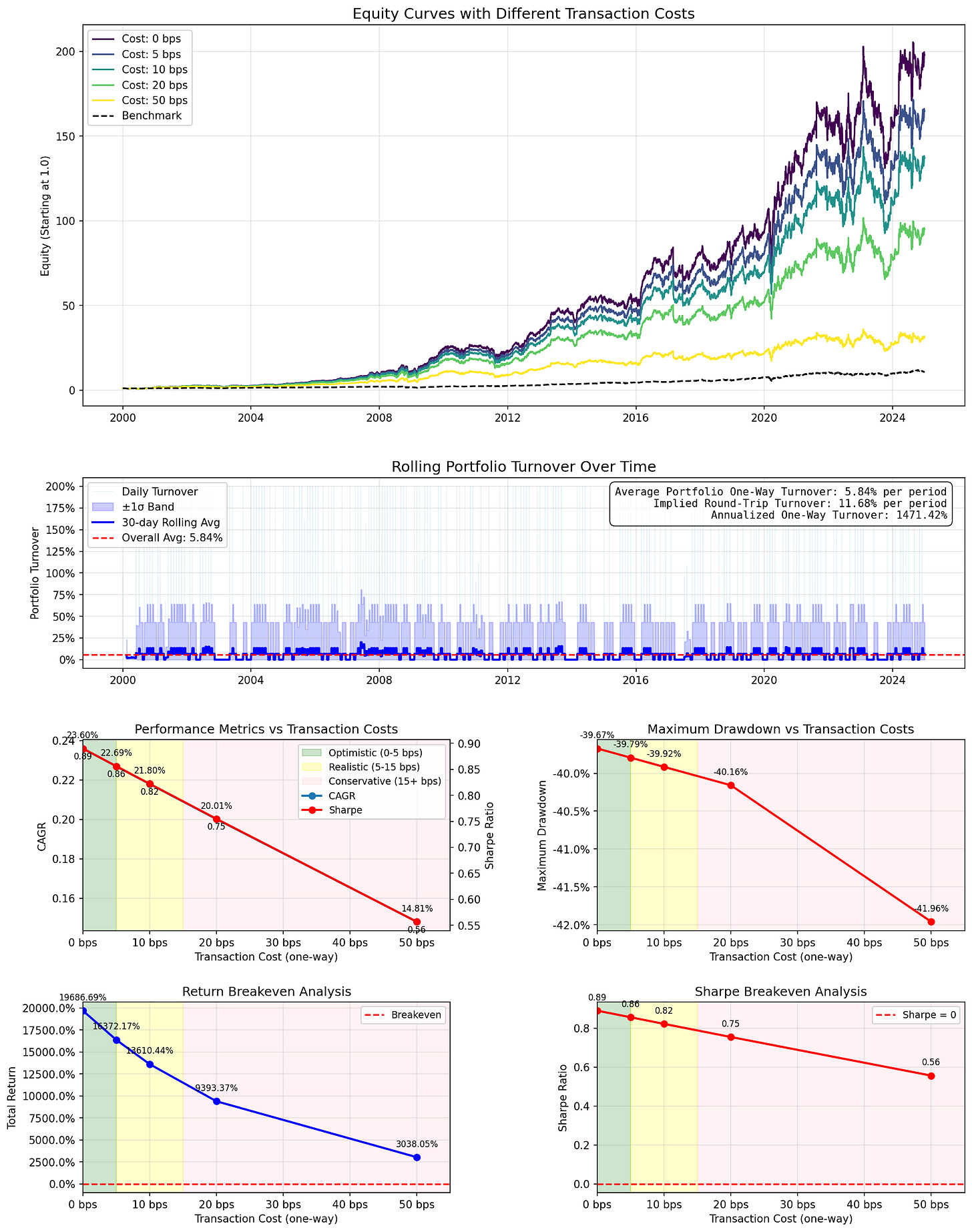
SquaredDiffMean
- 基于标准化差异`(SMA – EMA) / current_price`预测价格变动。预测价格 = `current_price * (1 + (SMA – EMA) / current_price)`。若SMA > EMA,意味着预测上涨。
- 超参数
- 90天回溯期
- 月度再平衡
- 含费用CAGR:21.80%
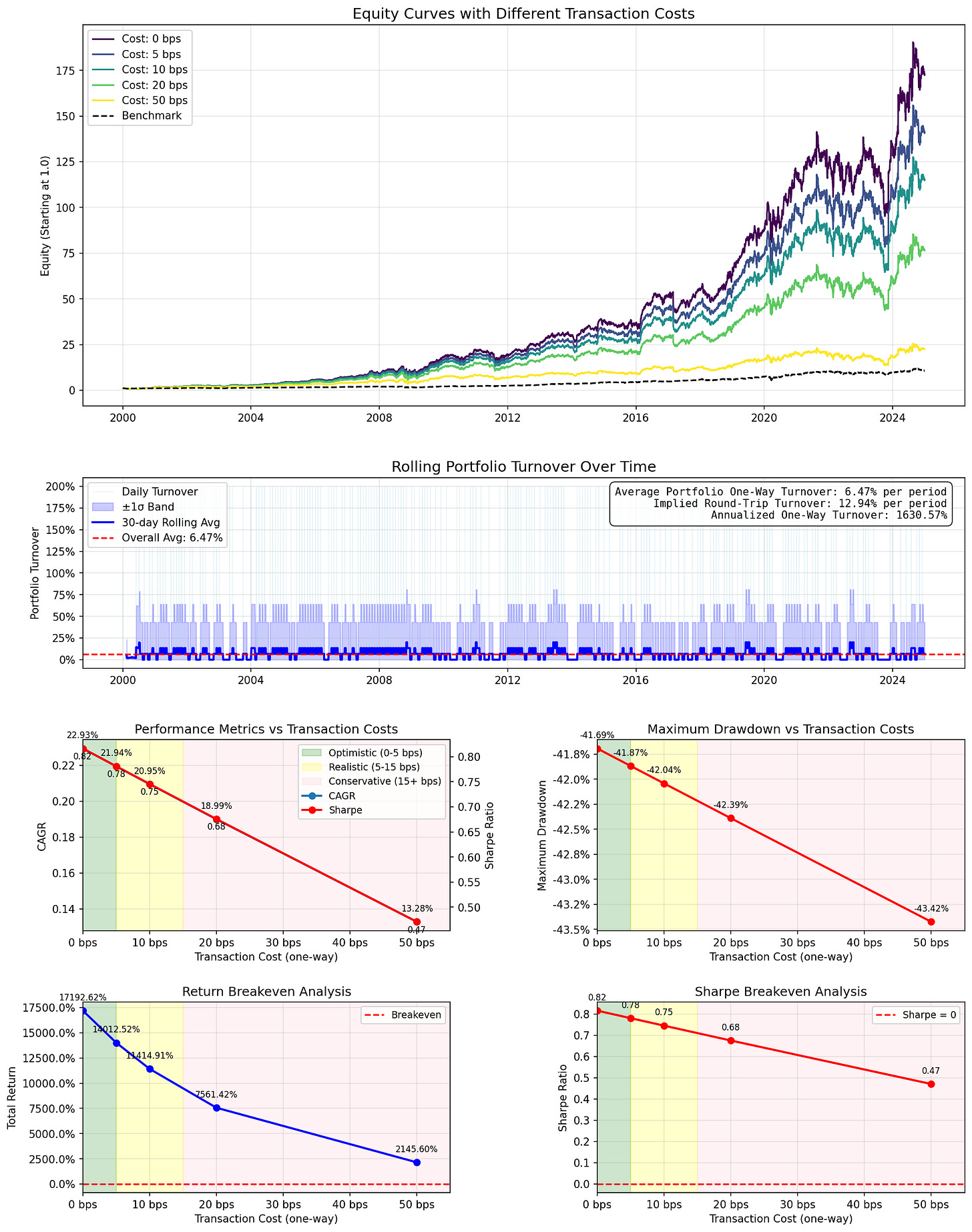
EntropyDivergence
- 计算资产回报的Shannon熵。低熵表明趋势,形成基于动量的预测;高熵表明噪音,形成向移动平均线回归的均值回归预测。
- 超参数
- 90天回溯期
- 月度再平衡
- 含费用CAGR:20.95%
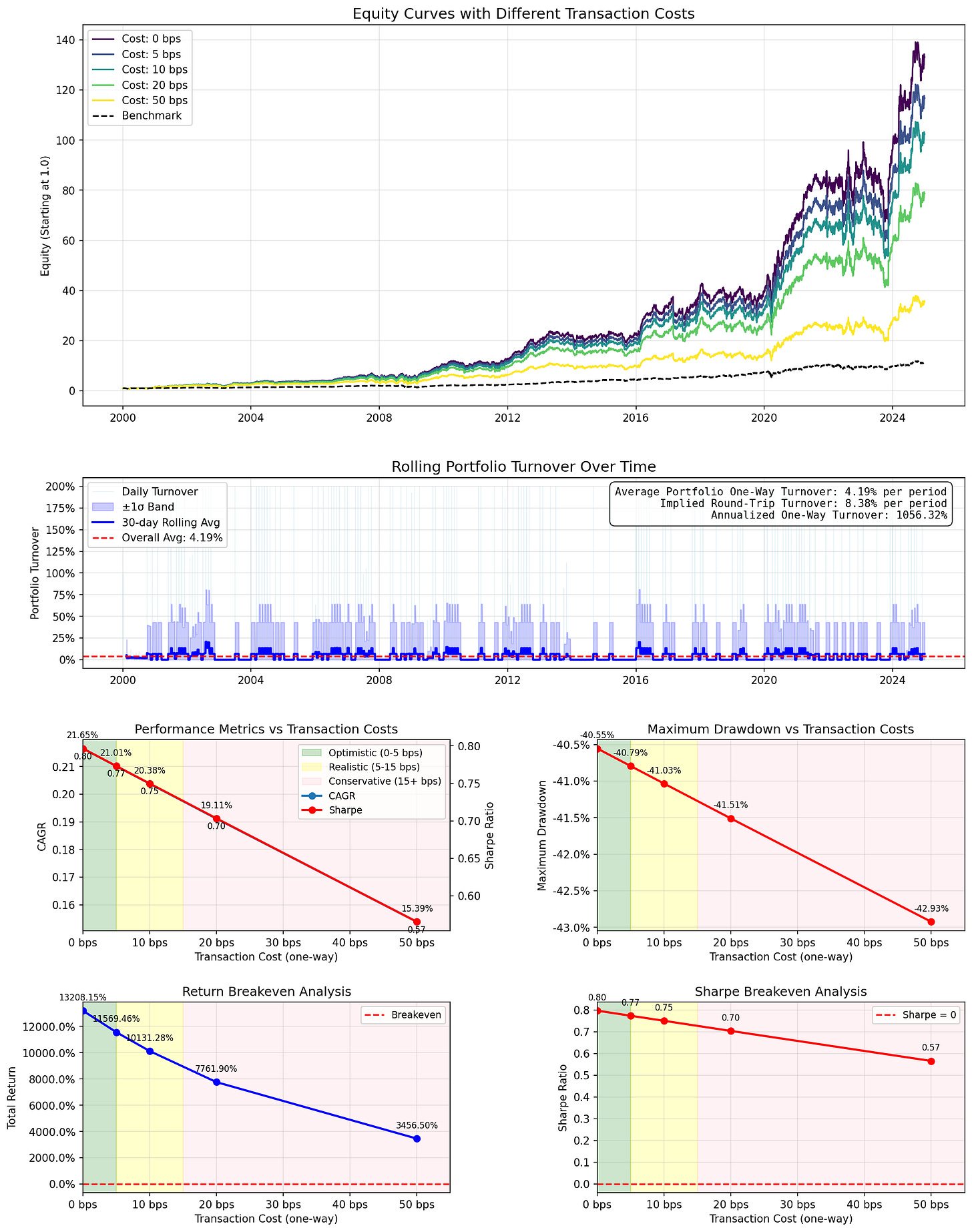
RecursiveEnvelope
- 递归更新包络线中心(当前价格的EMA,参数为`alpha`)及其宽度(`recent_vol / center`的EMA,参数为`alpha`)。预测当前平滑包络线中心。
- 超参数
- 180天回溯期
- 月度再平衡
- 含费用CAGR:20.38%
完整目录
为方便浏览,我创建了一个简单的静态网站,包含所有策略在各个时间框架下的预计算回测结果。你可以查看所有164种策略及其8种超参数组合。
点击下方按钮查看完整目录:
如果你喜欢这篇文章,请订阅以获取更多优秀的策略和交易内容。感谢你的支持!