Alpha Lab
数据:区间条、Renko条、过滤条和波动率条 [附完整代码]
金融条形图 第二部分
 𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗
𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗
2025年6月2日

 Trading the Breaking 数据:区间条、Renko条、过滤条和波动率条 [+CODE INSIDE]
Trading the Breaking 数据:区间条、Renko条、过滤条和波动率条 [+CODE INSIDE]

目录:
- 导言。
- 时间条的风险与局限。
- 信息驱动条的引入。
- 区间条。
- Renko条。
- 过滤条。
- 波动率条。
导言
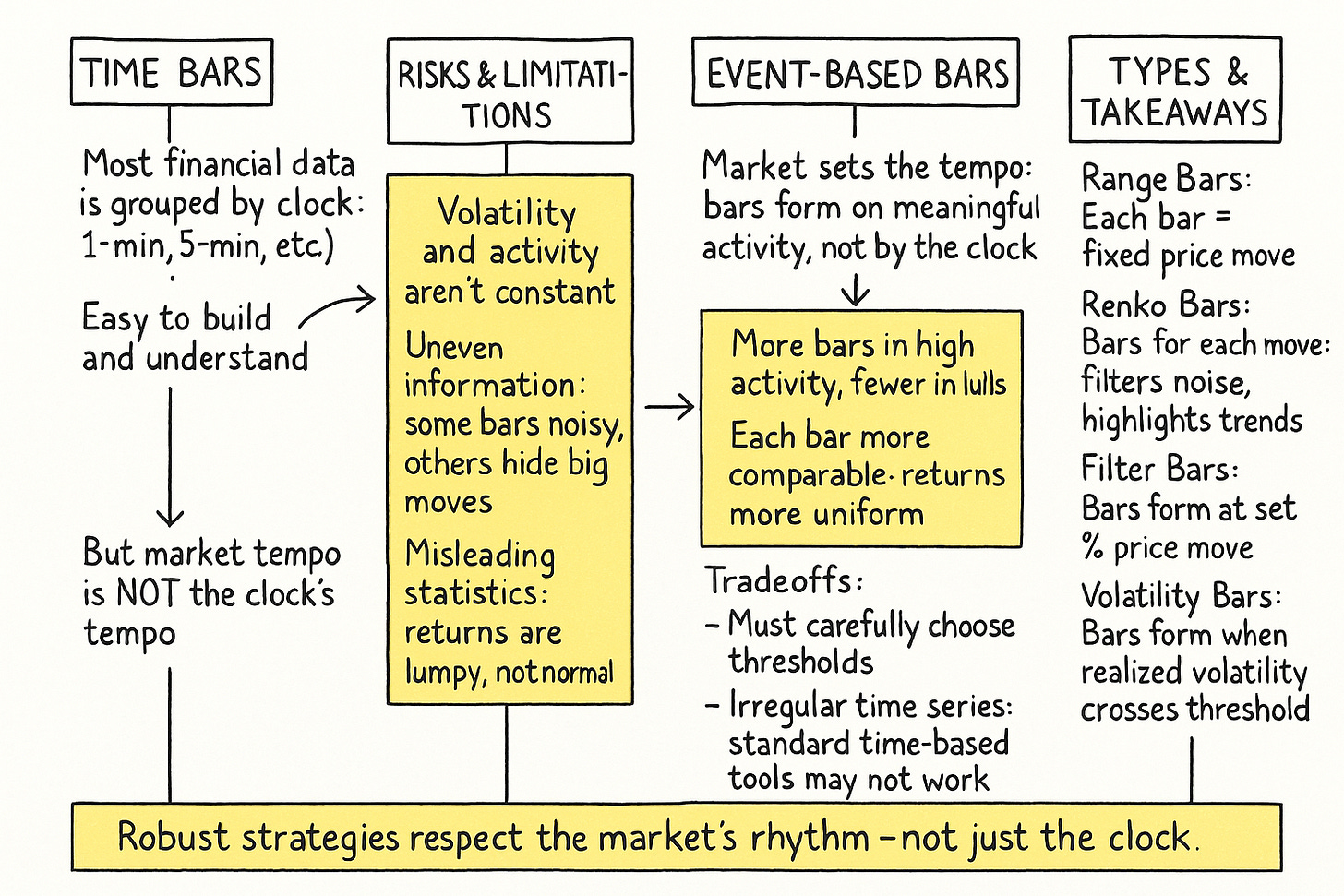
您正在实时观察市场——成千上万的价格跳动在屏幕上涌动,每一个都反映着供需和市场情绪的瞬时变化。乍一看,数据似乎均匀分布、结构规整。然而,在这表面之下隐藏着更深层的不对称性:市场活动的节奏并非由时钟的均匀节拍支配,而是由信息流和波动性的不规则脉冲驱动。
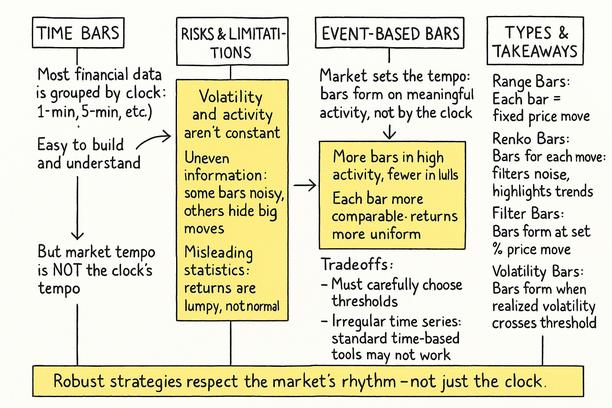
这一区别凸显了金融数据采样的一个根本挑战:时间(chronological time)与更恰当的称谓——市场时间(market time)——之间的不协调。虽然传统的时间条(time bars)——例如1分钟或5分钟间隔——提供了简洁性并与标准回测框架兼容,但它们假设每个时间单位都具有相同的信息权重。然而,现实远比这复杂。
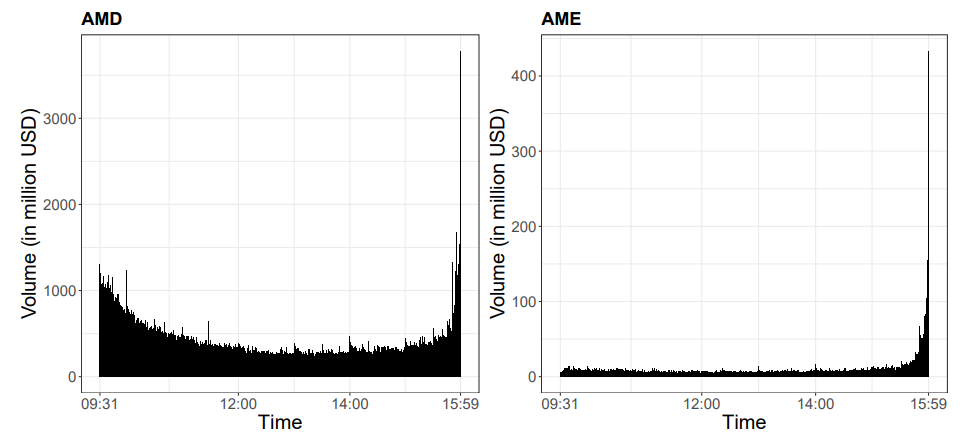
市场是事件驱动的。活动和波动性并非均匀分布。低流动性午间平静期的5分钟间隔与中央银行公告期间的5分钟窗口不等同。然而,在基于时间的采样中,两者被视为相同。这可能导致误导性信号,特别是对于对波动率机制或订单流敏感的策略而言。
此外,时间条引入了众所周知的统计复杂性。波动率聚类导致极端变动时期与平静时期在相同的时间单位内聚合,产生异方差的收益序列,从而损害风险模型、信号生成算法和机器学习架构的性能。例如,尝试在这些信息不均匀的数据上训练预测模型可能会产生不稳定或过拟合的结果。
替代方法,例如tick bars、volume bars和dollar bars,旨在通过根据市场活动而非时间流逝重新定义采样来解决这些缺点。Tick bars将固定数量的交易分组,适应市场参与的爆发。Volume bars聚合数据直到固定数量的股票或合约易手。Dollar bars更进一步,通过根据交易的名义价值进行聚合来标准化不同金融工具。这些方法倾向于产生更具统计稳定性的回报,并更好地与市场信息流保持一致。请在此处查看有关这些条:
 𝚃𝚛𝚊𝚍𝚒𝚗𝚐 𝚝𝚑𝚎 𝙱𝚛𝚎𝚊𝚔𝚒𝚗𝚐 数据:金融条形图 [附完整代码] 7天前 · 7个赞 · 𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗
𝚃𝚛𝚊𝚍𝚒𝚗𝚐 𝚝𝚑𝚎 𝙱𝚛𝚎𝚊𝚔𝚒𝚗𝚐 数据:金融条形图 [附完整代码] 7天前 · 7个赞 · 𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗
最终,选择合适的采样方法并非方便或否的问题——它是一个设计决策,它塑造了交易策略的行为、准确性和稳健性。虽然基于时间的条形图仍然很常见,但它们的局限性不容忽视。今天我们将回顾一种完全不同的条形图类型,其中一些在交易员中非常常见和流行。
时间条的风险与局限
超越基于时间的条形图,是为了探寻一种更智能的市场时钟,它不再随着秒的流逝而跳动,而是随着有意义事件的发生而跳动。其思想是,不仅当时间指示时采样观察结果,而且当市场做出有趣的事情时进行采样。这使我们进入了信息驱动条(information-driven bars)的概念,其中每个条都代表一个一致的“信息量子”,无论其如何定义——一定的价格变动、特定的交易量或特定数量的资本易手。
但是这条道路并非阳光普照的草地;它是一个迷宫,充满了诸多障碍。
- 价格变动多大才构成一个“有意义的事件”?
- 价格变动的“砖块”应该有多大?
- 何种程度的波动性才能形成一个新的条形图?
这些问题将算法交易者带入了参数选择的混沌之水,一个过拟合警报声 постоянно 响彻的领域。此外,这些条形图在时钟时间上的不规则出现会使传统的时间序列分析技术更难直接应用,需要对持续时间和季节性等概念采取新的观点。
传统上基于时间的条形图——例如1分钟、1小时——是历史默认设置。它们以固定的时间间隔采样价格数据。虽然易于计算和理解,但其核心缺陷在于假设市场活动在时间上均匀分布。这显然是错误的。市场表现出高活跃度和低活跃度时期,而基于时间的条形图对这些时期一视同仁。
考虑两个5分钟的条形图:
- 条形图A(低活跃度):价格在窄幅区间内徘徊。该条形图捕获的信息极少,可能只是噪音。
- 条形图B(高活跃度):新闻事件导致价格飙升和暴跌。该条形图捕获了显著的趋势和波动性,但将其挤压到与条形图A相同的时间框中。
这种差异导致算法模型出现以下几个问题:
- 回报的方差在条形图之间不恒定。假定同方差性的统计模型将被错误地指定。
- 基于时间的条形图的回报分布通常表现出超额峰度——肥尾——和偏度,偏离了许多金融模型所假设的正态分布。
- 在低活跃度期间,时间条会累积噪音。在高活跃度期间,固定间隔内重要的日内细节可能会丢失或被平均化。
错觉是我们正在测量市场;实际上,我们通常只是在测量时钟,将市场行为强行纳入任意的时间网格。因此,我们的目标是找到适应市场节奏而非外部节奏的采样方法。
信息驱动条的引入
信息驱动条(Information-driven bars),或事件驱动条(event-based bars),是根据信息流而非时间的流逝构建的——这里重要的是我们认为什么是信息。目标是创建每个条都代表类似数量的“市场事件性”的条形图。这种同步旨在产生具有更理想统计属性的条形序列,例如更接近独立同分布且理想情况下更接近正态分布的回报。
基本前提是重大的市场事件——价格变化、成交量激增、波动率飙升——才是真正重要的。通过根据这些事件形成条形图,我们让市场本身决定采样频率。当市场狂热时,条形图迅速形成,捕捉行动。当市场平静时,条形图缓慢形成,耐心等待有意义的信息。这种动态采样是价格变动条的标志。
以下Python代码片段概述了Hudson and Thames开发的基础类结构,我们将用它来构建所有条形图。此外,它还可以用于实现各种类型的信息化工具条,而不仅仅是López de Prado推广的那些。这说明了在分化为特定事件触发器之前的通用框架。
from abc import ABC, abstractmethod
import pandas as pd
import numpy as np
from collections import deque
def _batch_chunks(df, size):
"""
Split DataFrame into equal-sized chunks for batch processing.
"""
idx = np.arange(len(df)) // size
return [grp for _, grp in df.groupby(idx)]
class BaseBars(ABC):
def __init__(self, metric=None, batch_size=int(2e7)):
self.metric = metric
self.batch_size = batch_size
self.reset()
def reset(self):
self.open = self.high = self.low = self.close = None
self.prev_price = None
self.tick_rule = 0
self.stats = dict(cum_ticks=0, cum_dollar=0, cum_vol=0, cum_buy_vol=0)
def _sign(self, price):
if self.prev_price is None:
diff = 0
else:
diff = price - self.prev_price
self.prev_price = price
if diff != 0:
self.tick_rule = np.sign(diff)
return self.tick_rule
def run(self, rows):
bars = []
for t, p, v in rows:
self.stats['cum_ticks'] += 1
self.stats['cum_dollar'] += p * v
self.stats['cum_vol'] += v
if self._sign(p) > 0:
self.stats['cum_buy_vol'] += v
# initialize OHLC
if self.open is None:
self.open = self.high = self.low = p
# update
self.high = max(self.high, p)
self.low = min(self.low, p)
self.close = p
# check threshold
self._check_bar(t, p, bars)
return bars
def batch_run(self, data, to_csv=False, out=None):
cols = ['date', 'tick', 'open', 'high', 'low', 'close',
'vol', 'buy_vol', 'ticks', 'dollar']
bars = []
if isinstance(data, pd.DataFrame):
chunks = _batch_chunks(data, self.batch_size)
else:
chunks = pd.read_csv(data, chunksize=self.batch_size, parse_dates=[0])
for chunk in chunks:
bars.extend(self.run(chunk[['date', 'price', 'volume']].values))
df = pd.DataFrame(bars, columns=cols)
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
if to_csv and out:
df.to_csv(out)
return df
@abstractmethod
def _check_bar(self, t, p, bars):
...
这个BaseBars类巧妙地提供了一个公共引擎来累积tick数据,并将何时形成条形图的关键决定委托给其子类。这是设计我们自己的市场时钟的开端。

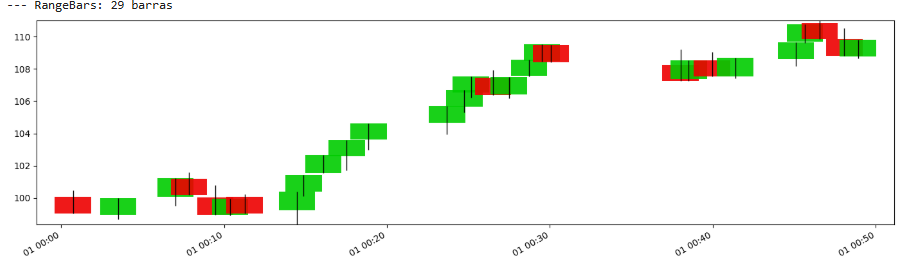
区间条(Range bars)
区间条是概念上最简单的价格变动条形图之一。当价格区间(最高价 – 最低价,或更常见的是正在形成的条形的 |Close – Open|)超过预定义阈值 R 时,形成一个新的条形图。
观察到tick i 时,关闭RangeBar k 的条件为:
\\(\text{close when}\;\bigl|\mathrm{close}_i – \mathrm{open}_k\bigr| \ge R \\)
其中 open k 是当前正在构建的条形的开盘价,而 close i 是当前tick的价格。
区间条的吸引力在于它们承诺每个条形图的价格变动均匀性。根据定义,每个条形图代表至少 R 的价格行程。这有助于标准化价格波动,使后续分析(如波动率估计或模式识别)更具一致性。
如果您想深入了解,请查看此PDF。我喜欢它的方法:

Volume Centred Range Bars
636KB ∙ PDF file
下载
下载
以下是RangeBars类如何实现此逻辑,它继承自BaseBars:
class RangeBars(BaseBars):
def __init__(self, threshold, batch_size=int(2e7)):
super().__init__(None, batch_size)
self.threshold = threshold
def _check_bar(self, t, p, bars):
if self.open is None:
return
if abs(self.close - self.open) >= self.threshold:
bars.append([pd.to_datetime(t), self.stats['cum_ticks'],
self.open, self.high, self.low, self.close,
self.stats['cum_vol'], self.stats['cum_buy_vol'],
self.stats['cum_ticks'], self.stats['cum_dollar']])
self.reset()
_check_bar方法是这里的核心。一旦价格从开盘点充分延伸,一个条形图就此“诞生”,并且过程重置,等待下一次 R 大小的行程。当然,挑战在于选择一个合适的 R。太小,你会被嘈杂的条形图淹没。太大,你会错过重要的细微之处。
我们来看看:
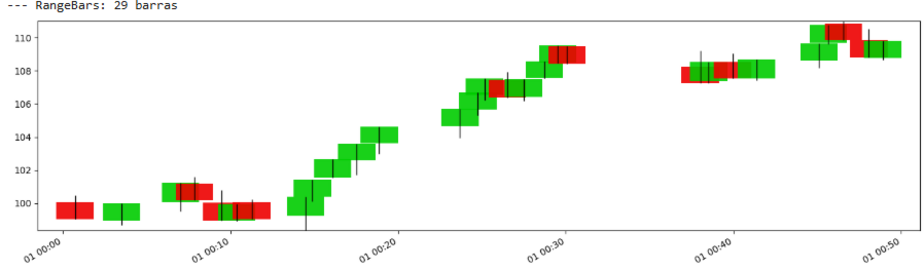
在高波动性期间,许多这样的条形图会在短时间内形成,而在低波动性期间,在较长的时间内形成的条形图会更少。
优点:
- 每个条形图——理想情况下——**代表着一致的价格波动量**。这有助于实现价格行为的标准化。
- 在高价格变动——波动性——时期会形成更多的条形图,而在平静时期会形成更少的条形图,这自然会**将采样重点放在行动发生的地方**。
- 固定的区间有时可以**帮助识别由区间量子 R 定义的微型支撑位和阻力位**。
- 通过要求最小的价格变动,一些较小的、**不那么重要的价格波动**可能会被过滤掉,相比于在平静市场中的时间条。
缺点:
- 区间阈值 R 的选择至关重要,并且通常与数据相关——工具、市场条件。不合适的 R 可能导致过多的——嘈杂的——条形图或过少的——细节丢失。
- 条形图不会在固定的时间间隔内收盘,这会使基于时间的分析或与基于时间的指标进行比较复杂化。
- 如果市场波动剧烈,但整体价格变动频繁地来回穿越 R 阈值而没有形成趋势,区间条形图仍然可能产生许多导致止损的信号。
- 如果价格进入一个远小于 R 的非常紧密的盘整阶段,条形图的形成可能会显著减慢或停止,可能会错过微妙的累积/派发模式。
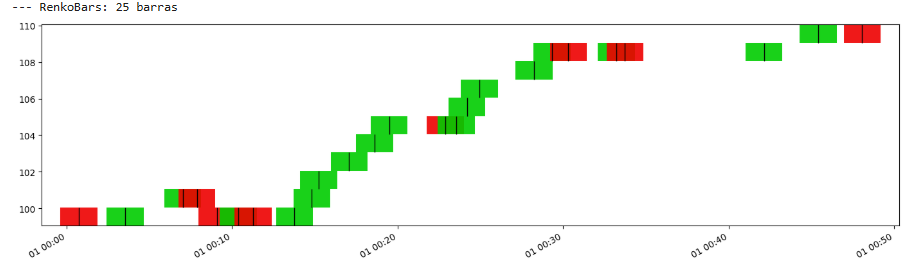
Renko条
Renko条,起源于日本——像Candlesticks一样——提供了一种独特的方式来可视化价格变动和识别趋势,通过过滤掉次要波动。它们由预定义固定大小 B 的“砖块”组成。只有当价格从上一个砖块的收盘价变动至少 B 时,才会添加一个新的砖块。如果价格朝当前方向变动 B,则会添加一个该颜色(例如,上涨为绿色,下跌为红色)的新砖块。关键的是,对于反转——反向颜色的砖块——价格通常需要向反方向变动 2 B——一个 B 来抵消当前砖块的方向,另一个 B 来形成新的砖块。提供的代码实现了一个更简单的版本,其中任何 B 的变动都会形成一个新的砖块。
条件是:每次自上次砖块收盘以来的累积价格变动 Δ p 达到砖块大小 B 时,就会发出一个新的砖块。
\\(\text{New brick when } |\text{current_price} – \text{last_brick_close}| \ge B\\)
RenkoBars类的实现:
class RenkoBars(BaseBars):
def __init__(self, brick_size, batch_size=int(2e7)):
self.last_close = None
super().__init__(None, batch_size)
self.brick_size = brick_size
def reset(self):
super().reset()
if self.last_close is not None:
self.open = self.high = self.low = self.close = self.last_close
def _check_bar(self, t, p, bars):
if self.last_close is None:
self.last_close = p
diff = p - self.last_close
direction = np.sign(diff)
num = int(abs(diff) // self.brick_size)
for _ in range(num):
o = self.last_close
c = o + direction * self.brick_size
bars.append([pd.to_datetime(t), self.stats['cum_ticks'],
o, max(o, c), min(o, c), c,
self.stats['cum_vol'], self.stats['cum_buy_vol'],
self.stats['cum_ticks'], self.stats['cum_dollar']])
self.last_close = c
super().reset()
self.open = self.high = self.low = self.close = c
Renko条擅长通过一系列相同颜色的砖块来突出趋势,以及支撑/阻力位。它们简洁、不杂乱的外观可能令人耳目一新,但时间的抽象意味着两个连续的砖块可能在几秒或几小时后形成。B 的选择再次至关重要。
我们来看看:
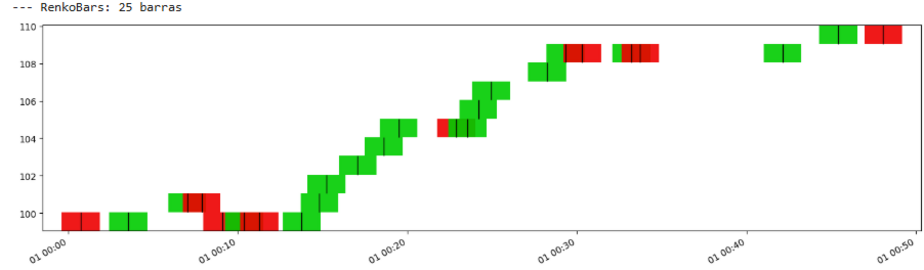
如您所见,Renko条和区间条非常相似。事实上,Renko条更平滑。
优点:
- Renko条通过过滤掉微小的价格波动,提供了非常清晰的趋势表示。一系列相同颜色的砖块是一个强烈的趋势信号。
- Renko条只关注至少大小为 B 的价格变动,从而有效消除噪声和与趋势相反的小幅回调。
- 砖块的水平线通常清楚地指示支撑位和阻力位。
- 统一的砖块大小和时间轴的移除使得条形图模式和趋势线非常清晰。
缺点:
- 砖块大小 B 至关重要。太小,条形图变得嘈杂;太大,则显著滞后,错过更精细的细节和进出场点。
- 特别是对于经典的Renko条,反转需要2 B 的移动,**信号可能会延迟**,导致进出场过晚。
- Renko条不显示时间周期内的确切最高价和最低价,只显示是否形成了砖块。所有导致新砖块无法形成的价格行为都会被忽略。
- 时间轴完全不规则。两个连续的砖块可能相隔数秒、数分钟甚至数小时形成,使得无法直接在Renko条上进行基于时间的分析。
- 处理缺口的方式可能有所不同,大开盘缺口可能会扭曲初始砖块的形成。
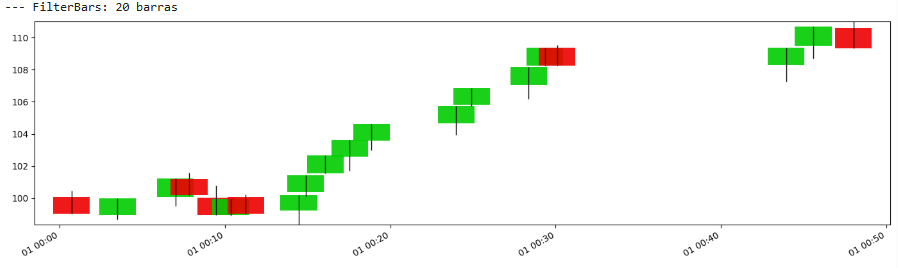
过滤条(Filter bars)
过滤条,有时被称为固定百分比条(Constant percentage bars)或对数价格条(Log-price bars)——尽管后者更具特指性——旨在当价格相对于基准价格 p base 变动达到一定百分比 θ 时形成新的条形图。这个 p base 通常是最后一个形成的条形的收盘价或当前条形的开盘价。
条件是:
\\(\text{close when}\quad \frac{\lvert p_i – p_{\mathrm{base}}\rvert}{p_{\mathrm{base}}} \ge \theta \\)
其中 p i 是当前价格。
这种类型的条形图很有趣,因为固定的百分比变动意味着不同的绝对价格变化,具体取决于当前价格水平。1% 的变动在10美元时是0.10美元,而在1000美元时是10美元。这可能更适用于波动性随价格缩放的资产。
FilterBars的实现:
class FilterBars(BaseBars):
def __init__(self, threshold_pct, batch_size=int(2e7)):
super().__init__(None, batch_size)
self.threshold_pct = threshold_pct
self.base = None
def reset(self):
super().reset()
self.base = None
def _check_bar(self, t, p, bars):
if self.base is None:
self.base = p
move = abs(p - self.base) / self.base if self.base != 0 else 0
if move >= self.threshold_pct:
bars.append([pd.to_datetime(t), self.stats['cum_ticks'],
self.open, self.high, self.low, p,
self.stats['cum_vol'], self.stats['cum_buy_vol'],
self.stats['cum_ticks'], self.stats['cum_dollar']])
self.reset()
过滤条动态调整形成新条形图所需的绝对价格变化,使其在不同价格区间或具有不同价格幅度的资产中更具鲁棒性。主要障碍仍然是 θ 的审慎选择。
我们来绘制一下:
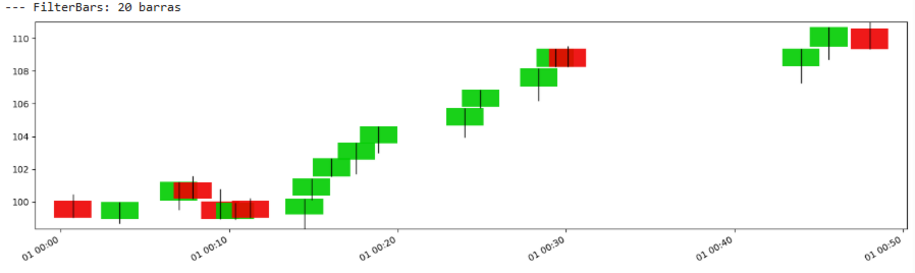
再一次,与之前的并没有太大区别。
优点:
- 固定百分比的变动考虑了1美元的变动对于10美元的股票比对于1000美元的股票更显著的事实。这使条形图在不同价格水平或波动性不同的资产之间具有可比性。
- 每个条形图代表相似的百分比变化,这对于某些侧重于相对价值或基于对数回报的信号的策略可能更具意义。
- 随着价格上涨,形成新条形图所需的绝对价格变化也随之增加——反之亦然。换句话说,当价格较高时,每个条形图需要更大的美元金额变动才能触发。
缺点:
- 百分比阈值 θ 的选择至关重要,需要仔细校准。
- 行为可能会微妙地改变,取决于 p base 是条形图的开盘价、前一个收盘价还是另一个参考。
- 像其他信息驱动条形图一样,它们不会在固定的时间间隔内形成。
- 如果 θ 设置得适合较高价格水平,它对于价格非常低的波动性资产可能仍然太小,导致产生许多条形图。相反,如果设置得适合低价资产,它在高价水平时可能过于不敏感。
- 如果 p base 非常小,则极端敏感。
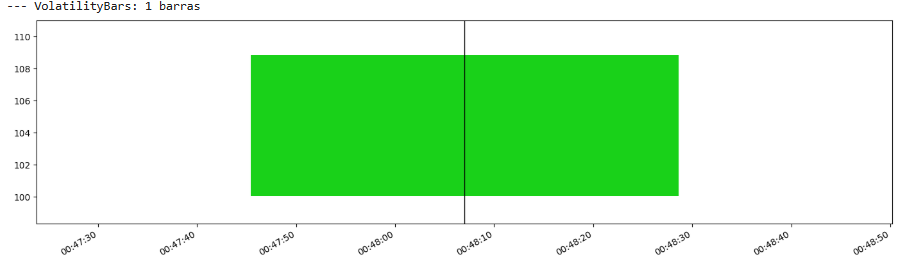
波动率条(Volatility bars)
波动率条采用更直接的方法来与市场状况同步。当在一定回溯窗口 W 内(以tick或时间为单位,但通常为tick以与条形图类型保持一致)观察到的波动率超过预定义的波动率阈值 σ 时,形成一个新条形图。
条件是:
\\(\text{compute }s = \operatorname{stdev}\bigl(\\{\,p_{i-W+1}, \ldots, p_{i}\\}\bigr) \quad \text{close if }s \ge \sigma \\)
这里,s 是最近 W 个刻度内价格的标准差。
这种方法直接解决了市场情绪变化的问题。当波动率高时,s 会更快达到 σ,导致条形图形成速度加快。当波动率低时,条形图形成速度减慢。这确保了每个条形图在某种意义上代表了相似的“惊喜”或风险量。
VolatilityBars的实现:
class VolatilityBars(BaseBars):
def __init__(self, vol_threshold, window, batch_size=int(2e7)):
# initialize window first so reset can clear it
self.window = deque(maxlen=window)
super().__init__(None, batch_size)
self.vol_threshold = vol_threshold
def reset(self):
super().reset()
self.window.clear()
def _check_bar(self, t, p, bars):
self.window.append(p)
if len(self.window) == self.window.maxlen:
vol = float(np.std(np.array(self.window)))
if vol >= self.vol_threshold:
bars.append([pd.to_datetime(t), self.stats['cum_ticks'],
self.open, self.high, self.low, self.close,
self.stats['cum_vol'], self.stats['cum_buy_vol'],
self.stats['cum_ticks'], self.stats['cum_dollar']])
self.reset()
波动率条直观上很有吸引力,因为它们直接适应市场行为最关键的方面之一。然而,它们引入了两个需要调整的参数:W 和 σ。W 的选择决定了波动率估计的响应性,而 σ 设定了条形图创建的灵敏度。
我们来看看:
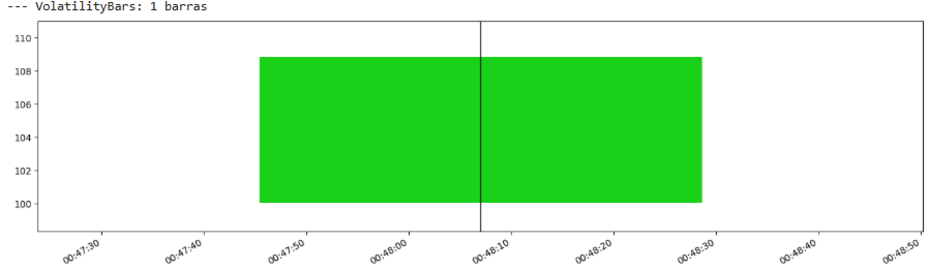
等等,什么!? 😕 数据量太少了,这个真是糟糕透顶…
优点:
- 当市场波动较大时,条形图的形成速度自然会加快,而当市场平静时,形成速度会减慢。这**将采样与市场“事件性”或风险对齐**。
- **每个条形图都试图捕捉类似数量的实际波动率**或意外。
- 可以导致条形序列中每条的tick数量或**条形图持续时间等量化属性具有更好的统计特性,以便进行建模**。
- **适用于在**高波动率与低波动率**机制下需要不同行为的策略**。
缺点:
- 需要设置用于波动率计算的回溯窗口 W 和波动率阈值 σ。这增加了优化复杂性和过拟合的风险。
- 虽然标准差很常见,但可以使用**其他波动率估计器,每个都有其自身的属性和影响**。
- 回溯窗口 W 会在波动率估计中引入一些滞后。较短的窗口响应更灵敏但噪音更大;较长的窗口更平滑但反应较慢。
- 所有信息驱动条的共同缺点,而且**它采样太慢**。
好的,区间条、Renko条、过滤条和波动率条提供的见解很有趣。它们解决了基于时间的采样无法区分剧烈活动和平静时期的核心问题。
- 通过设计,这些条形图旨在实现更稳定的统计属性——更接近IID、回报的正态性。这使得更可靠地应用统计学习模型和风险管理框架成为可能,因为这些框架往往会违反原始时间序列数据的假设。异方差性的诅咒,如果不是完全解除,也得到了显著缓解。
- 算法在使用这些条形图时,不再是被动地在固定间隔内监听,而是进行动态对话。它们在市场“坚定发声”时进行采样。这种适应性可以导致对新兴趋势的更快反应,并减少在盘整期间被噪音缠绕而止损的情况。这就像是定期检查和紧急响应系统之间的区别。
- 在这些更统一的信息单元上设计的特征——例如,N个信息条上的动量,N个信息条的波动率——可以比基于时间条的特征更稳健,并且在不同市场机制下更具可比性,因为时间条包含了截然不同的活动量。
这里的结论是:
1. 没有普遍的“最佳”条形图类型。
2. 最佳选择取决于特定的资产类别、交易策略的时间范围和逻辑,以及市场微观结构。
3. 趋势跟随策略可能更喜欢Renko条的清晰度,而突破策略可能更倾向于区间条或波动率条。
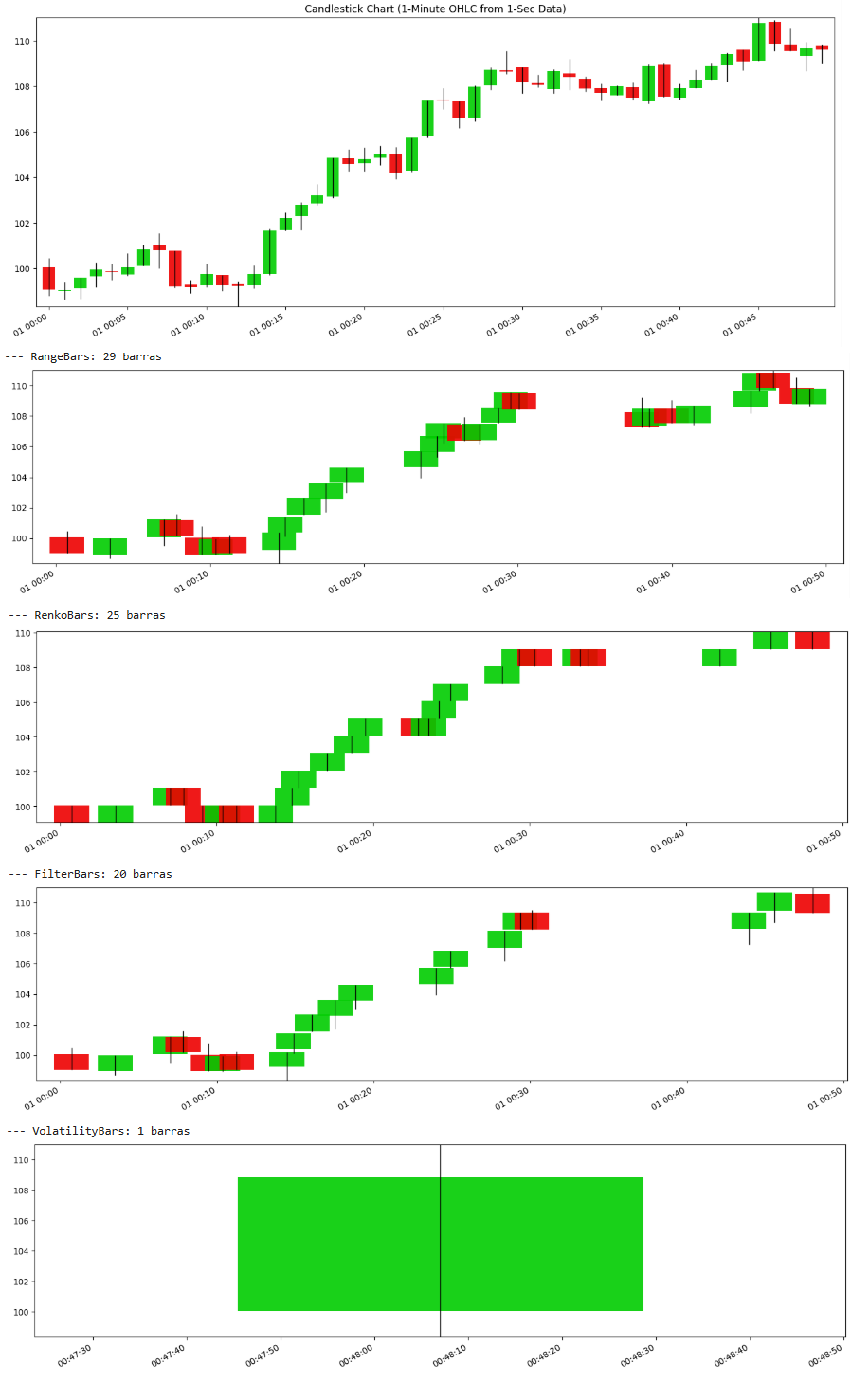
我们用视觉效果进行最终比较:
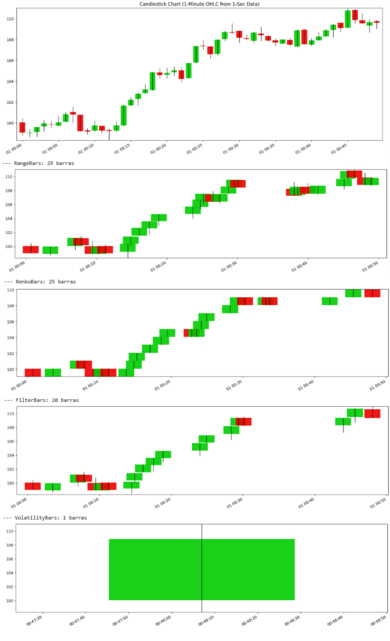
除了采样很慢的波动率条外,其余的条形图在视觉上产生了相当相似的结果。在下一期——这是2/3部分——我们将从统计学的角度深入探讨。
好的,团队!今天干得漂亮!是时候休息了。保持好奇,保持无限,保持量化!🕹️


 Trading the Breaking 数据:区间条、Renko条、过滤条和波动率条 [+CODE INSIDE]
Trading the Breaking 数据:区间条、Renko条、过滤条和波动率条 [+CODE INSIDE]
21
分享


Thierry Henkinet
3天前
我目前正在测试$bats,但“run bars”(受MLdP启发)已在我的计划之中。
𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗 的1条回复
1条以上评论…
版权所有 © 2025 𝚀𝚞𝚊𝚗𝚝 𝙱𝚎𝚌𝚔𝚖𝚊𝚗
隐私 ∙ 条款 ∙ 收集通知
获取应用
Substack 是优秀文化的发源地