我们终于能将ChatGPT用作量化分析师吗?
标签: AI, 资产配置, 资产类别选择, ChatGPT, 因子投资, 机器学习, 动量, 自研, 量化分析师, Smart Beta
在我们之前的两篇文章和文章中,我们探讨了利用人工智能回测交易策略的想法。自那以后,AI技术持续发展,像ChatGPT这样的工具已从简单的问答助手演变为可能有助于开发和测试投资策略的复杂工具——至少一些领域内较为乐观的声音是这样认为的。距离我们首次实验已过去一年多时间,鉴于目前围绕大型语言模型(LLMs)实用性的热议,我们认为现在是时候重新审视这一话题。因此,我们的目标是评估当今的AI模型作为准初级量化分析师的表现如何——不仅突出其有前景的用例,同时也指出仍然存在的局限性。
模型选择
首先,我们需要选择一个适合此任务的模型。我们探索了使用Claude AI、Gemini Advanced(前身为Deep Research)以及ChatGPT的选项,这些是当今使用最广泛的一些AI工具。AI模型的进步非常迅速;有些模型在特定子任务上表现更好,有些则较差;然而,从我们的角度来看,这些模型之间没有显著差异。因此,基于我们的需求——数据插补、代码解释和推理能力,我们选择了ChatGPT作为主要工具进行分析。在决定使用具体版本时,我们选择了GPT-4o模型,因为它整体上证明是最通用的。我们也考虑了GPT-4.5模型(OpenAI宣传其为更适合分析任务的模型),但由于它预计很快将被弃用,我们认为基于它撰写的文章不会有持久的相关性。
我们的目标
正如本文标题所暗示,我们的目标是探究AI是否可以协助创建交易策略的过程,或者即使不是整个过程,至少是否能将部分过程外包给AI,并且我们是否仍能信任其结果。为此,我们决定采用一个简单的模型——我们与ChatGPT合作,要求它协助我们创建一个资产配置策略,使用三种资产:股票、固定收益和商品。
我们的测试基于2015年7月7日至2025年4月17日的数据,投资组合包括SPY(SPDR S&P 500 ETF Trust)、IEF(iShares 7-10 Year Treasury Bond ETF)和DBC(Invesco DB Commodity Index Tracking Fund)。
初步尝试
当数据准备好后(我们遇到了一些问题,但稍后会总结),实施一个简单的交易策略,如固定百分比配置,是一项相对容易的任务。简单策略涉及不考虑市场条件,将固定比例的资本分配给不同资产。例如,你可能将60%的资金分配给股票,30%给债券,10%给商品。在代码中,这仅仅意味着将每种资产的回报乘以目标权重,然后相加得到投资组合回报。你不需要复杂的指标或动态再平衡,只需要对时间序列数据进行基本算术运算。这种策略非常适合AI自动化和测试的起步,因为逻辑简单且可以在数据集上统一应用。
AI模型还能做得更多。它不仅可以为这种基本策略编写代码,还能主动提出一些策略建议。因此,我们从一个朴素策略开始,并要求AI建议我们修改分配比例,这些比例是合理且合理的,并建议一些在回报、Sharpe比率和Calmar比率方面更具盈利性的策略。
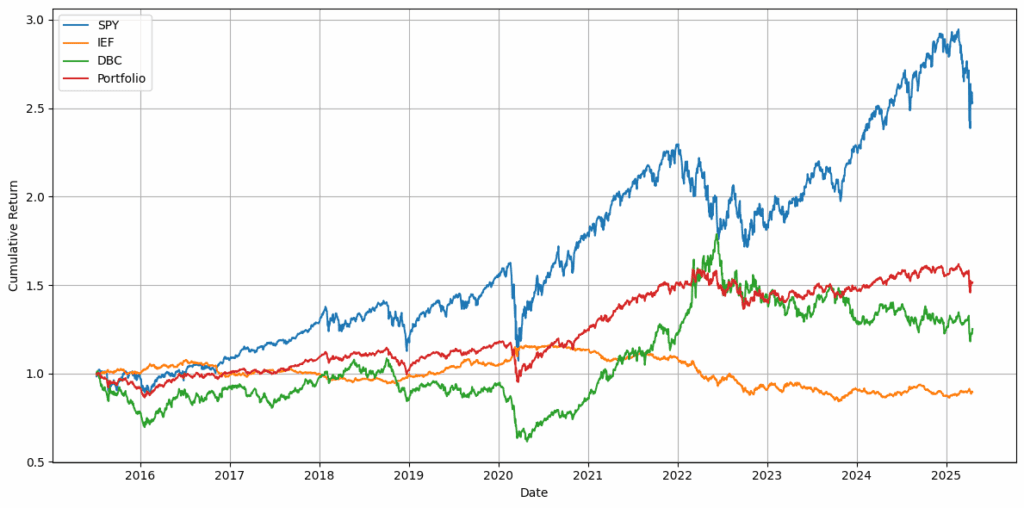
图1:投资组合中每种资产及朴素投资组合的权益曲线
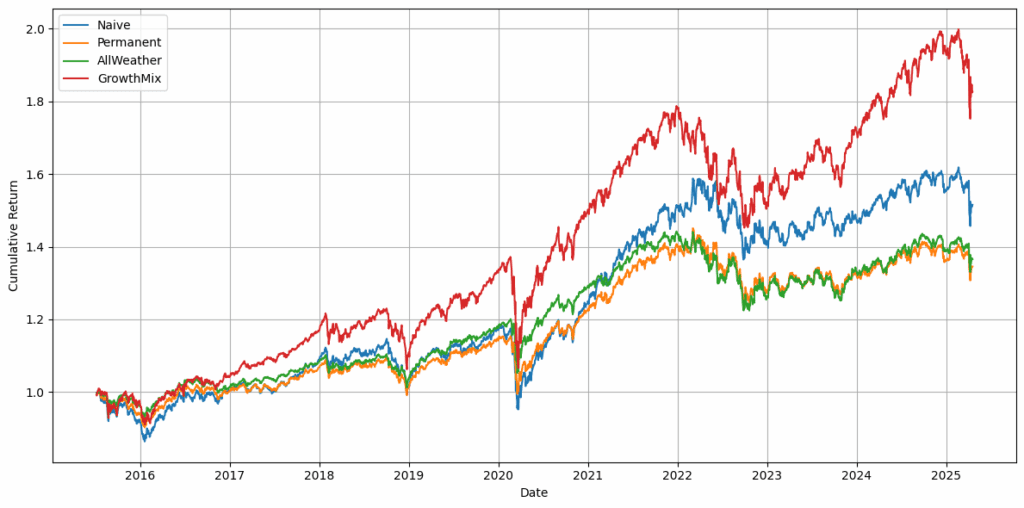
图2:AI建议的基本固定资产配置策略的权益曲线
建议改进
在运行基本的固定资产配置策略并检查其表现后,下一步显而易见:我们能做得更好吗? 创建一个固定权重的简单投资组合是一回事,但市场很少如此配合。因此,我们要求ChatGPT不仅测试朴素策略(及其变体),还要帮助提出可能改进结果的合理修改,而不使整个过程过于复杂。
这就是事情变得更有趣的地方。我们没有仅仅分配静态权重,而是探索了一些小的变化:如果在市场低迷时期稍微多配置一些债券,或者在强劲上升趋势中略微增加股票敞口会怎样?我们特意避免跳入复杂的机器学习模型或制度切换技术。这里的目标是适度引入足够的结构以反映现实世界的思维,例如根据近期表现或波动性进行调整。ChatGPT可以处理这些(尽管并非没有问题),但最终它能够建议重新配置投资组合权重或应用基本过滤器以避免重大回撤。通过这些提示,我们获得了以下权益曲线:
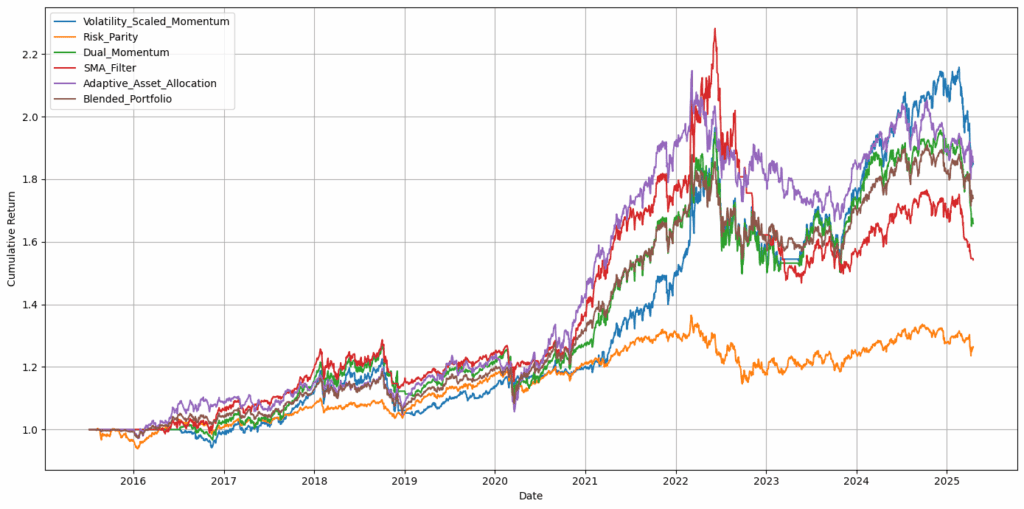
图3:高级策略的权益曲线
组合与优化
一旦我们看到主动资产配置策略可以提升表现,下一个挑战是找到一个更平衡的策略——不仅在纸面上表现良好,而且感觉上也稳健且合理。很容易陷入调整参数和选择指标的最佳周期以挤出略高的Sharpe比率,但总有权衡。一种策略在一个周期内看起来很棒,但在另一个周期内可能完全失效。
为此,我们要求ChatGPT帮助我们通过调整关键参数(在我们的案例中主要是时间框架)来测试策略的不同版本。我们的目的不是盲目优化以获得最佳结果,而是要了解策略对变化的敏感程度。如果参数的小幅变动导致表现大幅波动,那就是一个危险信号。
最终版本的根据ChatGPT的资产配置策略如下:

描述的策略具有以下特性:
| 策略 | 年化回报 | 年化波动率 | Sharpe比率 | 最大回撤 | Calmar比率 |
|---|---|---|---|---|---|
| Volatility Scaled Momentum | 6.49% | 11.93% | 0.5440 | -23.19% | 0.2800 |
| Risk Parity | 2.43% | 6.59% | 0.3686 | -16.07% | 0.1511 |
| Dual Momentum | 5.32% | 11.86% | 0.4484 | -23.19% | 0.2292 |
| SMA Filter | 4.54% | 11.46% | 0.3959 | -35.65% | 0.1272 |
| Adaptive Asset Allocation | 6.53% | 11.28% | 0.5790 | -22.41% | 0.2915 |
| Optimized Trend Following | 9.58% | 12.79% | 0.7491 | -20.55% | 0.4663 |
| Blended Portfolio | 5.83% | 9.38% | 0.6220 | -18.13% | 0.3217 |
表1:ChatGPT指导下的建议策略回报
以下是建议的主动策略和最终策略(棕色)的权益曲线:
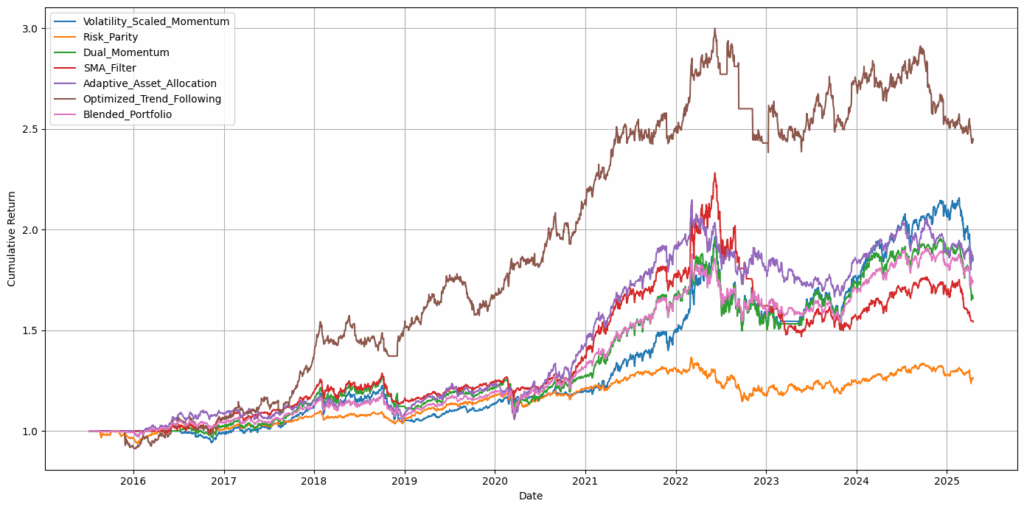
图4:高级策略与分析师指导策略的权益曲线对比
以下是AI执行稳健性测试的结果,以确保我们使用的参数窗口(如回溯周期或再平衡间隔)不是偶然选择导致异常结果的值。
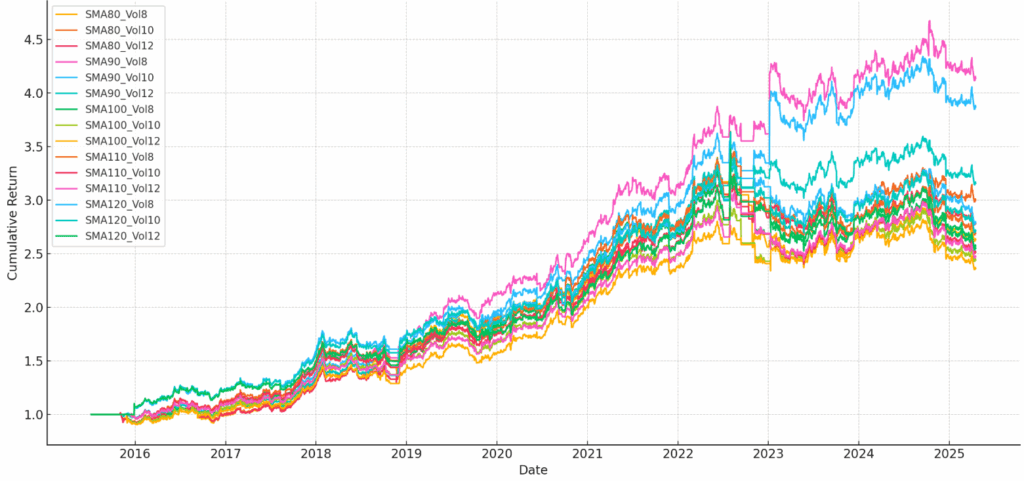
图5:ChatGPT策略的稳健性测试
表现良好的方面
到目前为止,这似乎是一个令人满意的故事,对吧?我们要求ChatGPT提供策略,最后我们得到了一个。相比大约18个月前我们进行的分析,整个过程无疑是一个显著的升级。ChatGPT在量化金融领域表现出色,可以为资产配置策略提出多种变化,并总能为分析的下一步提供建议。量化分析的探索部分处理得很好。ChatGPT是一个AI聊天机器人,因此它能够传达许多想法并进行雄辩的讨论。
然而,问题来了——它仍然是一个聊天机器人,而不是数据分析师,而且聊天机器人的主要焦点是让你对“聊天”感到满意。这意味着什么?它往往过于乐观和奉承——它不“思考”,它回答问题并试图让你愿意继续对话。很多时候,ChatGPT在提出其想法或分析时犯下极其幼稚的错误;然而,它却将结果呈现为有史以来最好的策略/想法。不断重新检查分析中的各个步骤真的很累人。
出现的问题
那么,我们遇到了哪些问题,当您尝试将聊天机器人作为量化金融的助手时应该注意什么?
数据准备
我们在处理数据时遇到了一些问题。最初,我们尝试通过ChatGPT直接从互联网获取数据,但这是不可行的——因此我们不得不自己提供数据。这导致了一些意想不到的问题。由于我们使用的日期格式为DD.MM.YYYY,数字的小数分隔符为逗号,ChatGPT在正确解释数据时确实遇到了困难。最可靠的方法是将数据提供为ChatGPT更熟悉的格式——通常日期使用YYYY-MM-DD,小数点使用点号。以这种方式准备数据集将使交互更顺畅,减少分析过程中的误解。
数据损坏
在输入的数据集上运行多个模型后,我们遇到了一些问题。在某些情况下,数据顺序意外改变;在其他情况下,数据的大部分被丢失。这导致输出明显不正确或与我们预期不一致。结果如下:
图6a和6b:数据损坏
这个问题与处理我们数据的内存工作方式密切相关。我们经常不得不重新上传相同的数据集,因为它在分析过程中被遗忘或以各种方式损坏(我们不了解损坏的原因)。这将使未来在测试中保持一致性变得更加困难,并突出了在这种设置中处理大型数据集的局限性。
最终,如果您想进行自己的测试分析,我们强烈建议为聊天机器人提供自己的数据。由于ChatGPT在初始数据处理中容易出错,如果您依赖ChatGPT本身的数据,您将无法发现它所犯的一些错误。
验证的必要性
在使用AI创建策略时,您通常希望绘制权益曲线,计算基本绩效指标等。然而,模型可能会以自己的方式解释这些任务,这并不总是符合您的预期。有时问题一眼就能看出来,但更多时候,您需要仔细检查代码。最常见的错误通常出现在数据格式化、策略功能的实现以及回报、风险和回撤的计算方式上。
另一个相关问题是理论上承诺过多,而在实际代码中交付不足。这通常意味着模型描述了例如由三个规则应用于数据集的策略,但只实现了其中的两个。在我们的案例中,策略本应包含动量、波动率和相关性。然而,相关性未在实现中使用。
幻觉(Hallucinations)
在AI的上下文中,这通常指模型生成的信息事实上不正确或捏造,尽管听起来可能合理。——ChatGPT
在我们的案例中,我们同时探索多种策略,并旨在仅分析其中最成功的表现。这种设置增加了错误被忽视的风险——尤其是当模型看似正确执行每个步骤,但实际上跳过或错误应用了策略逻辑的部分时。如果不仔细审查,这些不一致可能导致对策略有效性的误导性结论。

当我们获取此策略的代码并进行自己的分析时,我们得到的结果与模型有显著不同。
| 指标 | 数值 |
|---|---|
| 年化回报 | 1.74% |
| 年化波动率 | 2.58% |
| Sharpe比率 | 0.6760 |
| 最大回撤 | -7.89% |
| Calmar比率 | 0.2208 |
表2:在ChatGPT外部运行代码的结果
在第二次将数据上传到模型后,它产生的结果与我们的一致。ChatGPT第一次是如何计算出更好的比率的?为什么它们不同?我们不知道。
这让我们回到了分析过程中的一个重要部分——我们(用户,人类)必须在分析的每一步验证结果。无论这一步看起来多么微小或无关紧要,这都是绝对必要的。ChatGPT有时会产生完全捏造的数字(即使它为计算这些数字所建议的代码是正确的)。
循环对话
当我们发现计算的绩效指标有错误时,我们希望了解为什么会发生这种情况。在几次后续提示后,模型围绕各种解释打转——数据差异、策略结构的不一致或参数调整。然而,我们(正确地)指出这些都不适用,因为我们只是运行了ChatGPT提供的确切代码在最初提供的数据集上。即使要求模型在相同输入上重新运行其代码,我们发现自己陷入了一个循环,AI继续回避问题,而不是承认或纠正错误的计算。这表明使用AI调试或测试策略的一个关键限制:虽然它可能看起来自信,但它并不总是能可靠地追溯自身错误的原因。
如果我们退后一步,仅使用AI进行策略创意头脑风暴,我们可能会遇到类似的问题。模型往往会执着于一个基本概念,并倾向于围绕它构建一切。例如,如果我们从一个基于某个标准选择前N个资产的策略开始,模型可能继续只建议将此选择步骤视为必不可少的变体。除非我们明确表示不想使用该标准,否则它可能会一直是每个新提案的核心部分。这突出了一个常见的局限性:AI倾向于锚定初始方向,除非被明确引导,否则难以探索完全不同的想法。
过度优化的倾向
作为分析师,ChatGPT倾向于成为一台优化机器。它给出的建议或认为值得探究的想法往往会为策略增加自由度,因此策略越来越过度优化于过去的数据。ChatGPT(目前)无法很好地泛化,通常选择表现最佳的策略版本,然后寻找为何它是最好的解释,并试图进一步改进。从聊天机器人的角度来看这是合乎逻辑的,但如果你想构建一个稳健的交易策略,这并不是最好的想法。因此,ChatGPT的建议往往价值有限,通常最好提示它朝与它建议不同的方向继续。总的来说,分析时由人类掌舵比盲目依赖聊天机器人要好。
结论
人工智能是一个强大的工具,可以协助许多任务。它擅长自上而下地提出想法,为测试起草代码大纲,并在您遇到问题时偶尔帮助您找到新方向。然而,需要记住几个重要的局限性。例如,您仍然需要为分析自行提供数据,仔细检查代码中可能存在的许多错误,并且在未经验证的情况下不要完全信任模型输出的绩效指标(甚至图表)。
自从我们上一篇文章以来,AI取得了显著进展。它可以帮助自动化工作流程的部分内容并节省宝贵时间。然而,即使有了这些进步,错误的潜力仍然很高。这是您在尝试与之合作时需要计算的风险。AI是一个经典工具,就像一把锋利的刀——您可以用它制作许多有用的东西,或者如果您不知道自己在做什么,就可能割伤自己的手指。
作者:
David Belobrad, Quant Analyst, Quantpedia
Radovan Vojtko, Head of Research, Quantpedia
发表回复